ChatGPT is cool and popular. GPT-3 is the starting point for ChatGPT. Lets write something about me training a little version of GPT-3.
GPT-3 (Brown et al. 2020) has been popular for a while now, and has strangely become it’s own nested version of deep learning as a whole: Everyone was applying deep learning to everything, now everyone is applying GPT-3 to everything, and —related— everyone is applying transformers to everything (vision, audio, point clouds….bleh). I’m reminded of this ‘The Onion’ short where the Large Hadron Collider scientists get bored and are throwing random things into it: ‘…last week we threw a bird in there…’. 10% of machine learning research now seems to be “what if we trained a transformer like this?!”.
Strangely, GPT-3’s architecture is not all that complicated, or rather not much more than the original transformer architecture, and reading the paper and having it explained (“its just the decoder part…”) made me think that there must be more to it. Well, of course there is y’know all that engineering to train on 1000+ GPUs and such, but anyhow…
I wanted to actually run the code to see if there was an ‘ah, its a bit more complicated’ moment. I stumbled across Andrej Karpathy’s tutorial video about training a mini version of GPT-3 so I decided to watch and see if I could replicate the Shakespeare-sounding gobbledeygook coming out of the final model, and get some more practice with weights-and-biases along the way.
Ok, so obviously you should probably just go watch his video?…but…uh…I dunno maybe stick around for my sharp wit? I didn’t follow his build-the-transformer-from-scratch bits, which are good, but I’ve gone through all that already. Really I just wanted to do the things that make GPT-3 what it is:
- Form training tuples which are token sequences and next-token sequences.
- Feed the training tuples through masked self attention
- Generate some text from a prompt
The above three things plus scale are indeed almost all of what makes GPT-3 special. Here’s a link to the colab notebook for training this thing up. For fun I did some hyperparameter tuning as well.
Ok so I’ll briefly cover 1 - 3, but just go watch the video, it’s great.
(Aside: Andrej Karpathy’s video also convinced me to get Github Copilot, it auto suggested ‘just go watch the video, it’s great’ at the end of the last sentence. I’m not sure if I should be impressed or scared. I’m going to go with impressed. <- These two sentences also generated by copilot. This entire blog is written by copilot. Haha, just kidding, or am I? What is real? This is a blog post about GPT model partially written by a GPT-based model aaaaaaaaaaaaaaaaaaaaaaa!)
1. Basically, specify some maximum context length \(N_{max}\), grab \(n + 1: n < N_{max}\) ‘tokens’ (words, characters, subword tokens, etc), and make your input: tokens 1 to \(n\), and your targets tokens 2 to \(n + 1\). Something like this:
import torch
# Assume your tokens have been turned into integers, and we've sampled this sequence from the text
tokens = torch.tensor([10, 2, 23, 44, 15, 6, 57, 38, 19, 11])
inputs = torch.tensor(tokens[:-1])
targets = torch.tensor(tokens[1:])
logits = model(inputs.unsqueeze(0))
preds = torch.argmax(logits, dim=-1)
ce_loss = torch.nn.functional.cross_entropy(preds, targets)
# backward, zero_grad, step, etc.2. For masked self attention, we just want to pass an attention mask that makes it so every token can only attend to itself and tokens before it. The format is a bit strange, but it’s just a boolean tensor where the upper triangle is True and the lower triangle including diagonal is False (See the docs for further options). Here’s a quick way to make one:
attn_mask = torch.triu(torch.ones(block_size, block_size), diagonal=1).bool()
# then pass it to torch.nn.MultiheadAttention
attn_layer = torch.nn.MultiheadAttention(embed_dim, n_heads)
h = attn_layer(query, key, value, attn_mask=attn_mask)3. For generating text, we just need to start with some prompt, feed it in and get a prediction of the next token for every input token, then feed in the prompt + the predicted token, and get the next prediction, and so on.
prompt = torch.tensor([[10, 2, 23, 44, 15, 6, 57, 38, 19, 11]])
for _ in range(num_generations):
logits = model(prompt)
preds = torch.argmax(logits, dim=-1)
# only keep the last token and append it to the prompt:
prompt = torch.cat([prompt, preds[:, -1:]], dim=1)
# then you can decode the prompt back to text and see funny wordsHyperparameter Tuning
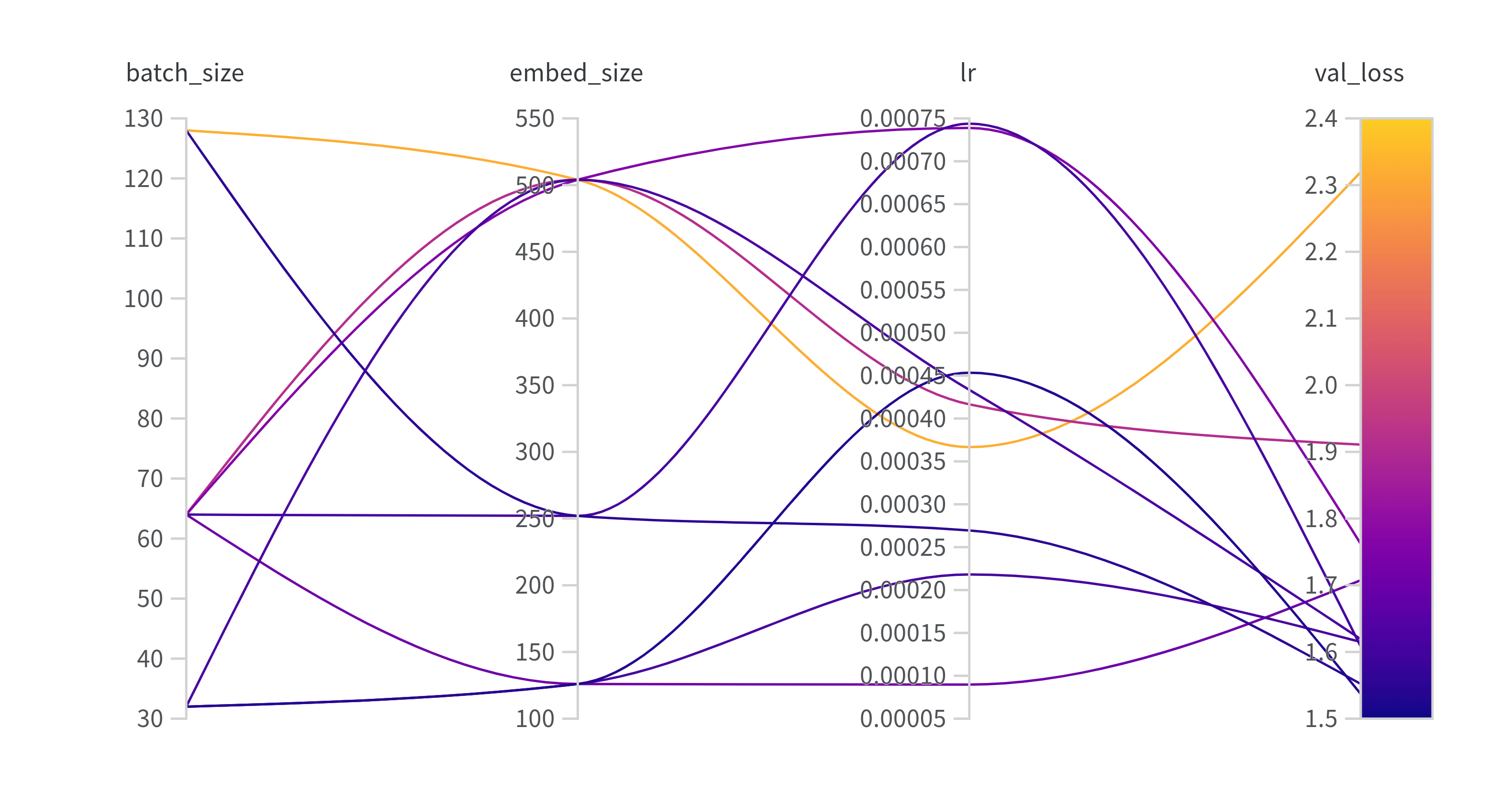
I sweep over hidden embedding dimension, learning rate, and batch size. The results of one of the sweeps can be seen here. There doesn’t seem to be much of a correlation between the hyperparameters and the validation loss. If I was doing another sweep I’d probably try varying dropout or max sequence length to see if I could recreate the validation loss.
Generated Text
I use the model from the run Radiant Rabbit to generate some text. The text is generated as described in 3 above, with a prompt of “LEONTES:”, a max length of 1000, and a block size of 128. Notice below I am passing an increasingly large mask and feeding a maximum of 128 tokens at a time. The model has not seen sequences longer than 128 tokens, and would begin to produce nonsense (or rather, even more nonsensical nonsense) beyond that length.
idx = torch.tensor(encode("LEONTES:\n")).unsqueeze(0).to(device)
block_size = 128
for i in range(1000):
attn_mask = torch.triu(torch.ones(idx.size(1), idx.size(1)), diagonal=1).bool()
attn_mask = attn_mask[:block_size, :block_size].to(device)
logits = m(idx[:, -block_size:], attn_mask = attn_mask)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, 1)
idx = torch.cat([idx, idx_next], dim=1)I promised some funny text, here’s a snippet of the decoded output:
LEONTES:
True!
O worse of this men it.
DUKE VINCENTIO:
Gentle king him!
Provost:
No more of ourself in a say 'nointed,' silent visit,
In carrion choose with ever of person;
He hath had made her heads, that nature's away:
Therefore, had I in my vain sweet prevent
To see her friends did close his minds.
Provost:
O though this, if I do wish a sword knowledge
In wanton common can my blate to some have
based with said, but that it bloody billows,
Ratter lieuted with a moler'd and enmity
May have utter'd my heart
By from the testy-moning hour, whom
More comes not thus? beitterly od married.
MAMILLIUS:
Lear out?
LEONTES:
Nay, God help.
Serving Servant:
He's sometime now:
The judge hate I, being in become moads,
'gainst enjoying warps it, and venture,
These stocks, tears; and it may be feen gone,
but the master of his old return in
And bear me those his grace, that knows be call'd
The queen amorous of burthen and walking at him.
Dear most respect this prince hour? If then
penter this member what hDANIEL:
Daniel out?